An Introduction to Artificial Intelligence and Machine Learning
Artificial Intelligence
First coined in 1956 by John McCarthy, Artificial Intelligence (AI) broadly describes computer systems that have the ability to perform tasks that mimic human intelligence. Creating computer systems that can successfully reason, plan, represent knowledge, learn, process natural language and perceive are all major goals of active AI research.
We can think about the general evolution and progression of Artificial Intelligence in terms of three different types or forms of intelligence:
Artificial Narrow Intelligence or ANI exhibits partial or limited characteristics of human intelligence, but can be effective when applied to specific types of problems. Facial recognition software, recommendation systems and digital personal assistants are examples of narrow intelligence.
Artificial General Intelligence or AGI would exhibit all of the characteristics of human intelligence, and may even exhibit degrees of human consciousness. AGI would excel at most problem solving tasks and activities and may exhibit self-learning and self-adaptation behaviours.
Artificial Super Intelligence or ASI represent systems that would far exceed the characteristics of human intelligence. The extent to which ASI systems exceed human intelligence is speculative, as is the pace at which AGI may transition into ASI.
Machine Learning
Arthur Samuel popularized the term Machine Learning (ML) in 1959 as a field of computer science that gives computers the ability to learn without being explicitly programmed, and specifically focuses on the design and construction of algorithms that can both learn from and make predictions on data. Machine Learning is an approach towards achieving Artificial Ingelligence. A more formal definition of Machine Learning was produced by Tom Mitchell in 1998:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Put simply, if a computer program can improve the performance of a task by using previous experience you can say that the program has learned from the experience.
The ability for software to learn and improve from experience is significantly different from how traditional software is written. ML enables the development of new types of applications that would either be impractical or impossible if the same application were to be programmed explicitly using traditional software engineering techniques and methods.
Machine Learning Strategies
There are generally considered to be three distinct machine learning strategies or ways to think about solving specific types of problems. Let's broadly describe how these strategies work, and provide some insight into the problems they intend to solve.
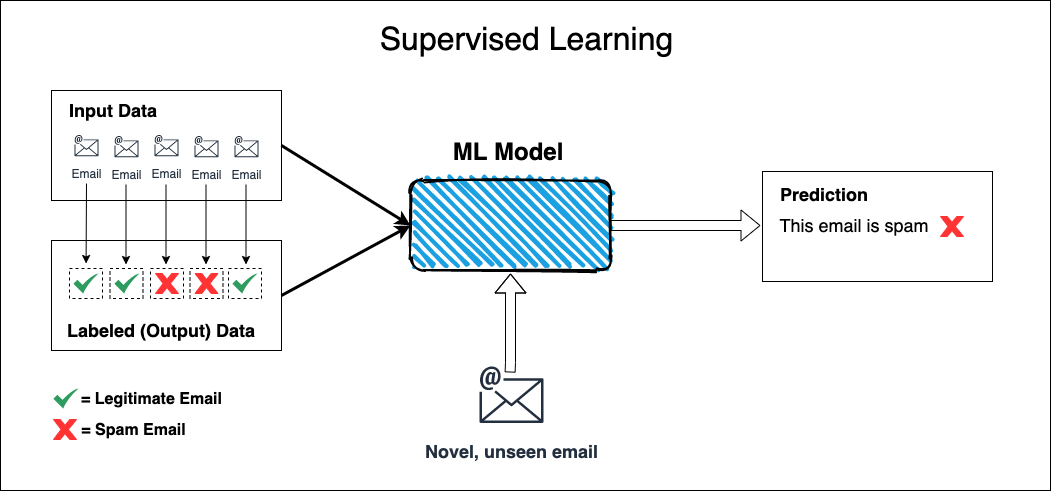
Supervised Learning
Supervised learning is effective at solving problems where you cannot meaningfully express or identify relationships in your data with a discrete set of rules or heuristics. While it might be easy for you to tell whether an email in your inbox is spam or not, it’s difficult to develop traditional software with an explicit and concrete set of rules to achieve the same outcome. Supervised machine learning algorithms are effective at addressing and solving these types of problems.
Supervised learning uses pairs of input and output data, with an expectation or hypothesis that some form of relationship exists between the input and output. A supervised learning algorithm trained with a set of input and output pairs aims to discover relationships between the inputs and outputs, and then make predictions with novel inputs that it has not been exposed to before.
For example, a spam filtering algorithm needs to be trained with sets of emails that have been assessed and assigned as either spam or not spam - data pairs that contain defined or assigned output are referred to as labelled data. It is the use of labelled data that characterizes supervised learning and differentiates it from other machine learning strategies. All supervised learning algorithms must be trained with labelled data in order to act as useful predictive tools.
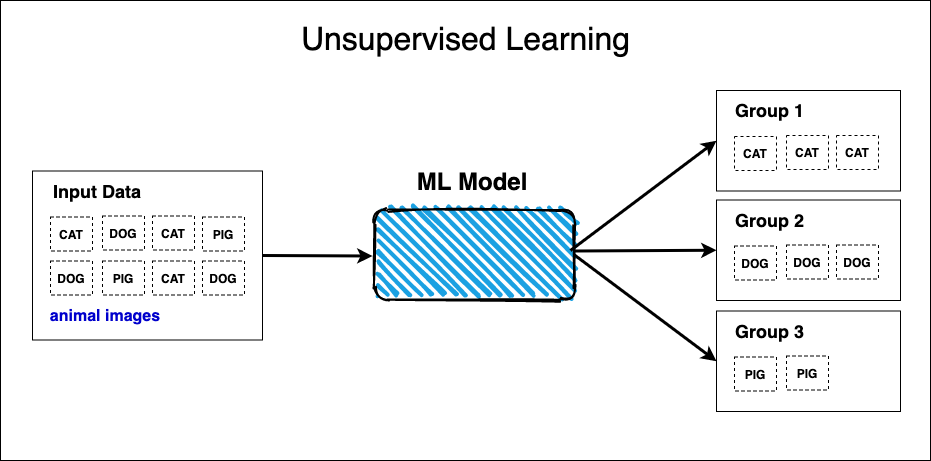
Unsupervised Learning
Unsupervised learning is effective at solving problems where you cannot meaningfully identify or discover patterns in your data with a discrete set of rules or heuristics. While it might be easy for you to tell whether you’re looking at a picture of a cat or a dog, it’s difficult to develop traditional software with an explicit and concrete set of rules to do the same.
Put simply, we can say that unsupervised learning is an effective strategy for solving discovery problems. Unsupervised learning algorithms work to discover novel patterns or structures in data that would be impractical or even impossible using traditional programming techniques.
Unsupervised learning models are primarily used to group, cluster or segment data. Instead of making predictions like “this is an image of a cat”, “this is an image of a dog” or “this is an image of a pig”, these models will predict the most likely group an image belongs to. The resulting clusters or groups of images are unlabeled; it would be up to a human to assign a label for each of the clusters.
Reinforcement Learning
Reinforcement learning is a modern machine learning strategy that uses goal-oriented algorithms that learn how to accomplish an objective over many steps. These algorithms are penalized when they make the wrong decisions and rewarded when they make the right ones.
Reinforcement learning algorithms are not provided with training sets ahead of time. In the absence of training data, these algorithms learn from experience by collecting data from their environment through trial and error; they observe and dynamically adapt to the environment around them.
In this respect, reinforcement learning algorithms share a similar data-driven learning approach as supervised learning algorithms; while supervised learning algorithms learn from data ahead of time, reinforcement learning algorithms learn from data as it becomes available in their environment.
The ability for software to dynamically learn from and adapt to changes in an environment makes reinforcement learning algorithms well suited for advanced problem spaces like autonomous vehicle design, robotics and supply chain optimization.
Machine Learning Models
When we talk about Large Language Models, Generative AI Models, or the process of building, training and deploying models, the term model represents a specific solution that can predict or anticipate future behaviour, based on the statistical analysis of historical data.
Supervised learning makes use of classification and regression models, while unsupervised learning makes use of clustering and dimensionality reduction models. Let’s broadly describe how these models work and provide some insight into the problems they solve. You’ll learn more about these models and the algorithms that underpin them in upcoming chapters.
Classification Models
Classification models work by predicting discrete values from well-defined and finite sets of possible outcomes. In other words, classification algorithms predict the best group for an object, given all of the possible groups an algorithm is allowed to choose from. Classification models could be used to predict whether an email should belong to a spam group or not spam group, or which automotive brand a picture of a car belongs to.
Regression Models
Regression models work by predicting continuous values. A continuous value is a real value, such as an integer or floating point number. Regression algorithms will often predict quantities, such as amounts and sizes. Regression models could be used to predict the value of residential real estate, or whether the value of a stock should rise or fall to a specific price.
Clustering Models
Clustering models are used to assign objects to groups while ensuring that objects in different groups are not similar to each other. Clustering models share similar goals to classification models - both models aim to assign an object to a group. Where classification models assign objects to pre-defined groups, clustering models assign objects to groups that are dynamically identified and created by the model itself. Clustering models have practical applications in many areas including recommender systems, fraud detection and bioinformatics.
Dimensionality Reduction Models
Dimensionality reduction models are used to reduce the number of features or variables under consideration in statistical machine learning models and have a number of practical applications within the domain of machine learning itself. Feature reduction can be achieved by feature selection where a subset of features are selected from the existing features, or by feature extraction where features are extracted by combining existing features.